
Веб-краулеры или «пауки» — это компьютерные программы, которые автоматически обходят страницы в Интернете и собирают информацию для поисковых систем. Они играют важную роль в процессе индексации веб-сайтов и определении их рейтинга.
Однако постоянные запросы от веб-краулеров могут негативно влиять на производительность и доступность веб-сайтов, особенно для маленьких и слабых серверов. Для решения этой проблемы была разработана директива Crawl-delay.
Crawl-delay — это инструкция, указываемая в файле robots.txt, который настраивает скорость сканирования веб-краулеров на конкретном веб-сайте. Она определяет задержку между запросами от пауков и позволяет веб-сайту контролировать частоту, с которой их боты выполняют сканирование. Это позволяет управлять нагрузкой на сервер и минимизировать негативное влияние краулеров на сайт.
Директива Crawl-delay: что это и как она работает
Данная директива предоставляет возможность веб-мастерам ограничивать частоту запросов от бота к их сайтам. Она определяет, сколько времени поисковая система должна ждать перед тем, как сделать следующий запрос. Это полезно для сайтов с ограниченными ресурсами или находящихся на медленных серверах, которые могут быть перегружены большим количеством запросов.
Установка директивы Crawl-delay происходит путем добавления строки «Crawl-delay: X» в файл robots.txt, где X — это задержка в секундах. Например, «Crawl-delay: 5» означает, что между запросами бот должен делать паузу в 5 секунд. Однако, не все поисковые системы учитывают и выполняют эту директиву, она не совсем стандартизирована и ее реализация может отличаться от поисковика к поисковику.
Существует также альтернативная директива для задержки между запросами — «Request-rate». Она устанавливает количество запросов в минуту, которое поисковая система может делать к сайту. Например, «Request-rate: 60/1m» означает, что бот может делать не более 60 запросов в минуту.
Раздел 1. Определение и цель директивы Crawl-delay
Цель использования директивы Crawl-delay заключается в управлении частотой и интенсивностью обходов, а также снижении негативного влияния на сайт: повышении времени отклика сервера, уменьшении использования полосы пропускания и сокращении нагрузки на хостинг. Использование Crawl-delay позволяет улучшить производительность и стабильность работы сайта, а также повысить его общую скорость загрузки страниц.
Основные преимущества использования директивы Crawl-delay:
- Оптимизация использования ресурсов — позволяет управлять частотой обращения робота к серверу, что помогает избежать превышения лимитов и расхода полосы пропускания.
- Предотвращение блокировки — учитывая задержку между запросами, можно избежать активации механизмов блокировки сервера, которые могут возникнуть при интенсивном обходе.
- Улучшение производительности — снижение серверной нагрузки и оптимизация ответов сервера способствуют более быстрой загрузке страниц и улучшению пользовательского опыта.
Раздел 2. Влияние директивы Crawl-delay на индексацию сайта
Директива Crawl-delay в файле robots.txt используется для указания задержки между запросами к сайту от поисковых роботов. Она влияет на индексацию сайта и может быть полезна в случае, когда сервер неспособен обрабатывать большое количество запросов одновременно или когда веб-мастер хочет ограничить индексацию сайта определенными роботами.
Когда робот поисковика обращается к сайту, он сначала проверяет файл robots.txt в корневой директории сайта. Если в нем присутствует директива Crawl-delay, то робот будет ждать указанное количество секунд перед отправкой следующего запроса. Это позволяет снизить нагрузку на сервер и предотвратить временные проблемы с доступностью сайта.
Если на сайте указана директива Crawl-delay, то роботы поисковых систем будут индексировать его более медленно. Это может привести к тому, что некоторые страницы сайта будут обновляться в индексе реже, чем без использования директивы Crawl-delay. Поэтому перед использованием такой директивы следует внимательно оценить негативное влияние на индексацию и учесть его при оптимизации сайта для поисковых систем.
Некоторые поисковые системы, такие как Google и Yandex, не поддерживают директиву Crawl-delay и игнорируют ее. Однако, она может быть полезной для других поисковых роботов, особенно для тех, которые не установлены веб-мастером идентифицировать. При использовании директивы Crawl-delay важно указывать реалистичное значение, чтобы не создавать проблемы с индексацией сайта.
Раздел 3. Как использовать и настраивать директиву Crawl-delay
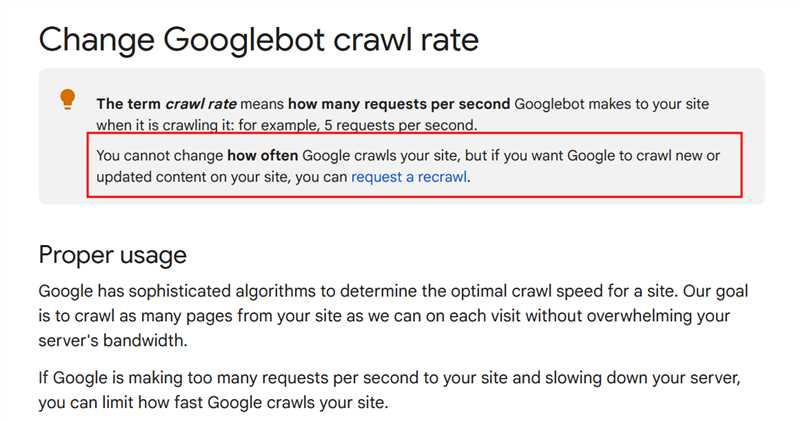
Директива Crawl-delay используется для задания задержки между запросами поисковым роботам на сканирование страниц сайта. Это позволяет управлять скоростью сканирования и предотвращать перегрузку сервера. Эта директива полезна в случае, если у вас есть большой сайт с огромным количеством страниц или если вы хотите управлять доступом к определенным разделам сайта.
Для использования директивы Crawl-delay вам понадобится файл robots.txt. В этом файле вы можете определить время задержки для каждого поискового робота. Для этого вам нужно указать название робота после директивы User-agent, а затем задать задержку с помощью директивы Crawl-delay.
Пример:
User-Agent: Googlebot Crawl-delay: 5 User-Agent: Bingbot Crawl-delay: 10
В этом примере мы задали задержку в 5 секунд для робота Google и 10 секунд для робота Bing. Это означает, что каждый раз, когда эти роботы обращаются к нашему сайту, между запросами проходит указанное время.
Как правило, большинство поисковых систем уважает правила из файла robots.txt и устанавливают задержку, указанную в директиве Crawl-delay. Однако стоит отметить, что не все поисковые системы поддерживают эту директиву, поэтому она может не иметь влияния на скорость сканирования некоторых роботов. Также стоит учесть, что директива Crawl-delay не ограничивает число запросов, а только задает интервал между ними.
В итоге, использование и настройка директивы Crawl-delay может быть полезным инструментом для контроля скорости сканирования поисковыми роботами и предотвращения перегрузки сервера. Она позволяет оптимизировать работу сайта и обеспечить более гладкое взаимодействие с поисковыми системами. Однако необходимо учитывать, что эта директива может не иметь влияния на всех роботов и не ограничивает число запросов.
Наши партнеры: